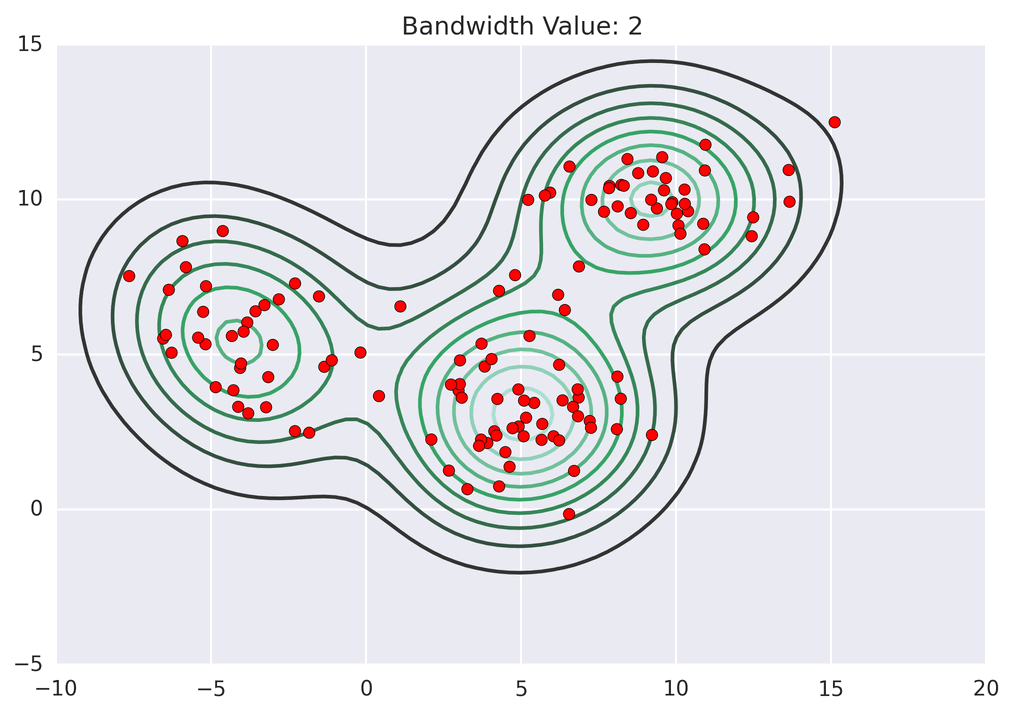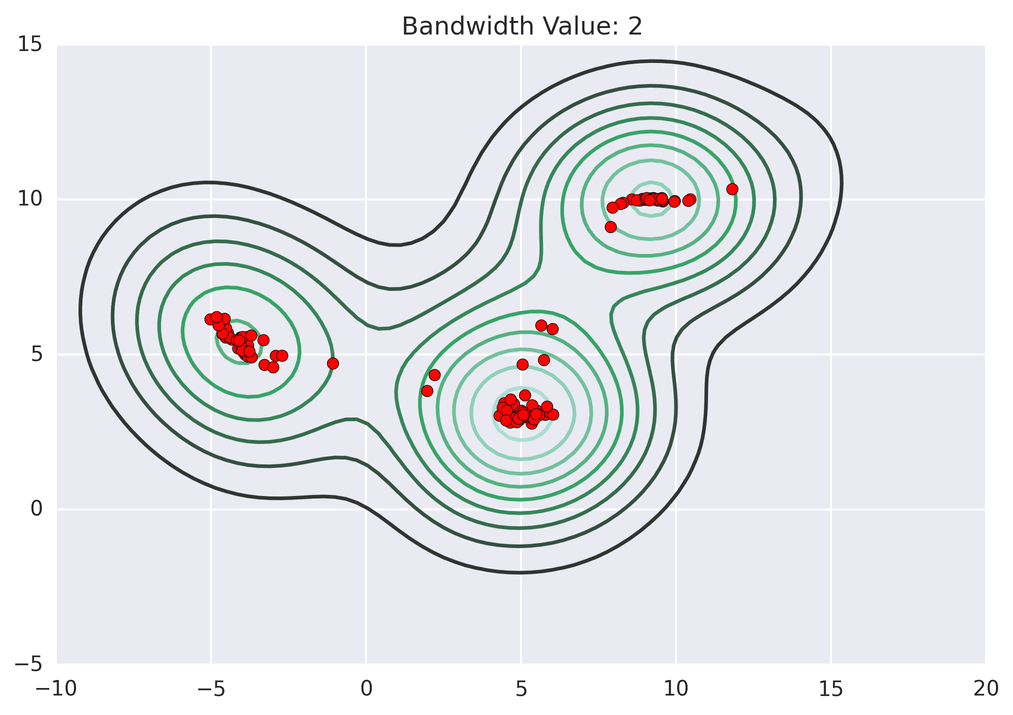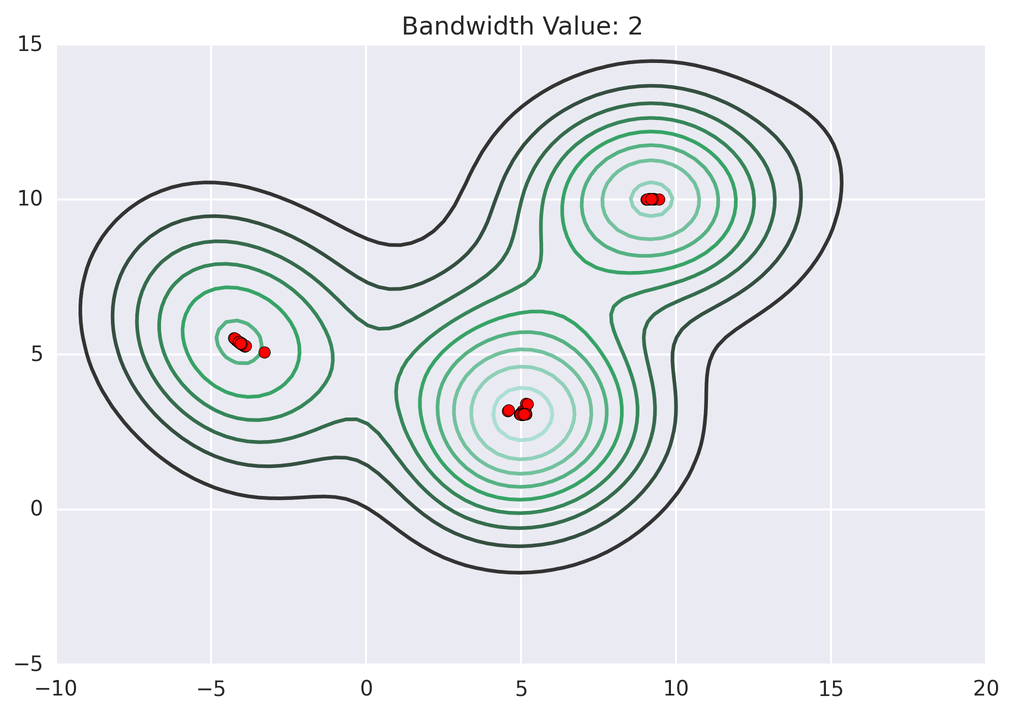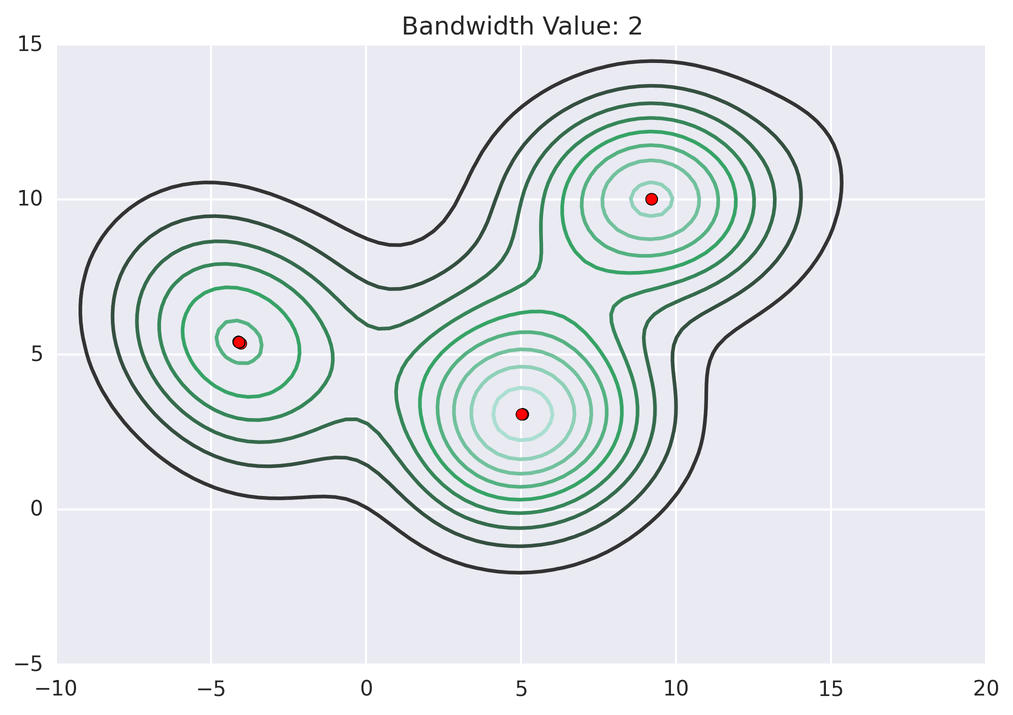
Next: Deep Learning without CUDA.. → MeanShift Clustering: a GPU case-study January 12, 2018 Redirecting to /news/msg